

Snowflake and the Pursuit Of Precision Medicine
Snowflake
NOVEMBER 29, 2023
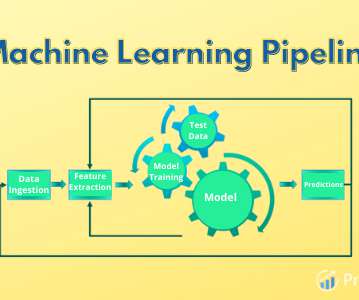
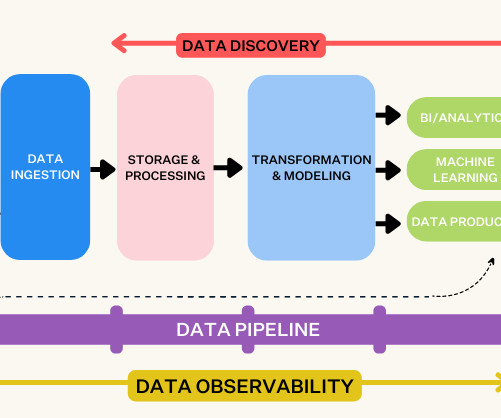
For example, the data storage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. The principles emphasize machine-actionability (i.e.,













































Let's personalize your content