

Snowflake’s New Python API Empowers Data Engineers to Build Modern Data Pipelines with Ease
Snowflake
APRIL 17, 2024
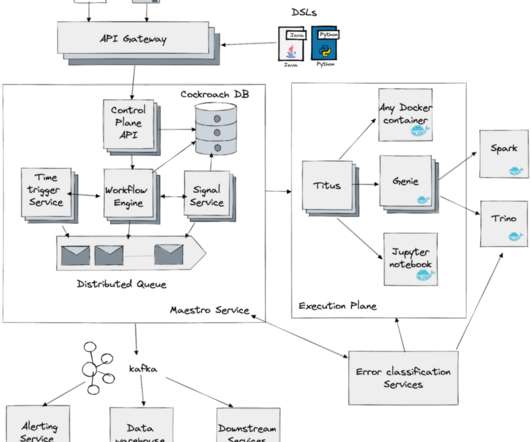
Since the previous Python connector API mostly communicated via SQL, it also hindered the ability to manage Snowflake objects natively in Python, restricting data pipeline efficiency and the ability to complete complex tasks. Or, experience these features firsthand at our free Dev Day event on June 6th in the Demo Zone.





































Let's personalize your content