
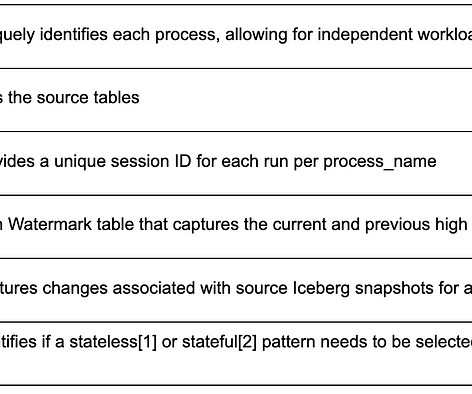
2. Diving Deeper into Psyberg: Stateless vs Stateful Data Processing
Netflix Tech
NOVEMBER 14, 2023
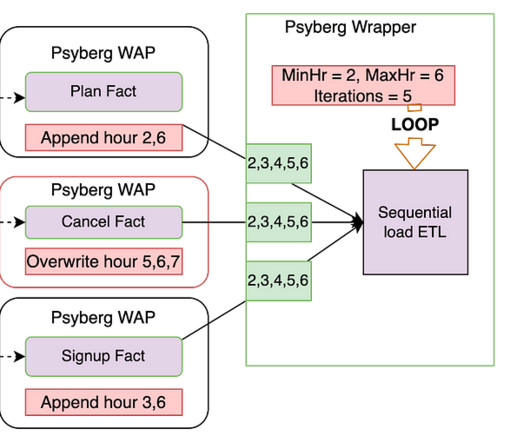
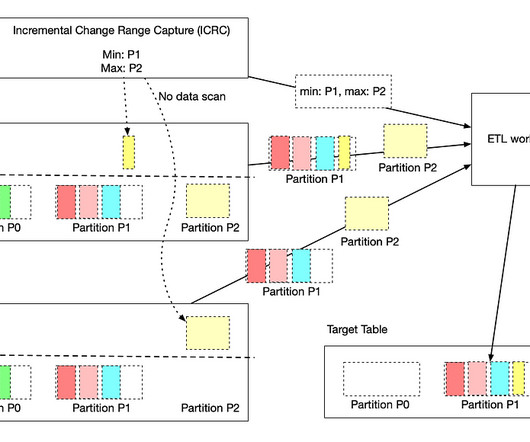
Understanding the nature of the late-arriving data and processing requirements will help decide which pattern is most appropriate for a use case. This information has only one source, and we can append new/late records to the fact table as and when the events are received.








































Let's personalize your content