
Data Lakes and SQL: A Match Made in Data Heaven
KDnuggets
JANUARY 16, 2023
In this article, we will discuss the benefits of using SQL with a data lake and how it can help organizations unlock the full potential of their data.

KDnuggets
JANUARY 16, 2023
In this article, we will discuss the benefits of using SQL with a data lake and how it can help organizations unlock the full potential of their data.
KDnuggets
JUNE 27, 2022
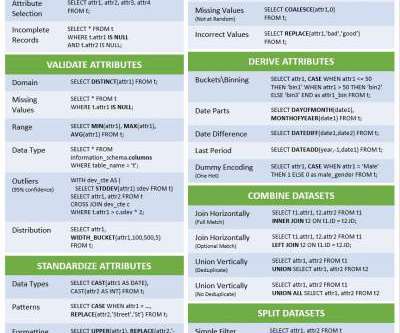
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Data Engineering Podcast
AUGUST 3, 2021
Summary Data lake architectures have largely been biased toward batch processing workflows due to the volume of data that they are designed for. With more real-time requirements and the increasing use of streaming data there has been a struggle to merge fast, incremental updates with large, historical analysis.
phData: Data Engineering
SEPTEMBER 19, 2023
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a Data Lake? Consistency of data throughout the data lake.

Monte Carlo
APRIL 24, 2023
Data lakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.

DareData
JULY 5, 2023
Learn how we build data lake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.

AltexSoft
AUGUST 29, 2023
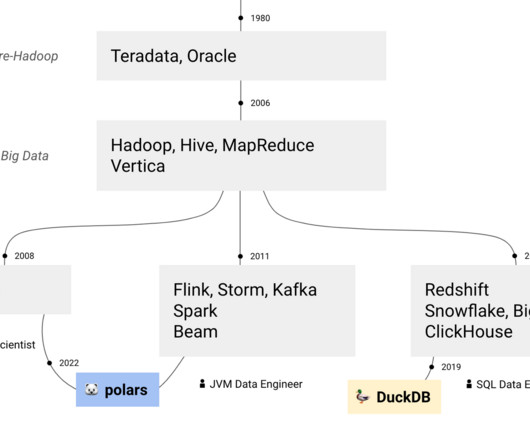
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a data lake?

Expert insights. Personalized for you.




































Let's personalize your content