
Using Kappa Architecture to Reduce Data Integration Costs
Striim
AUGUST 31, 2023
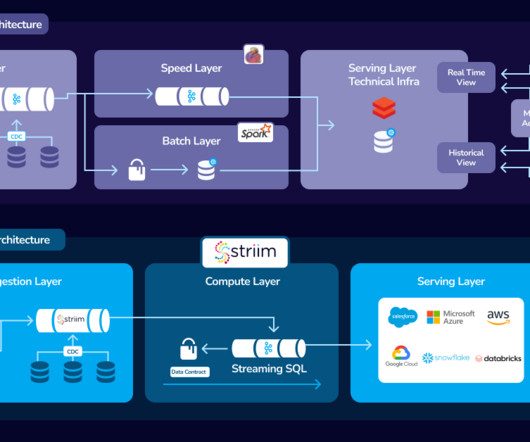
In this article, we will take a look at the benefits and drawbacks of kappa architecture, how Striim makes it easier to use, what infrastructure you need for your kappa architecture, and how you can start designing your own kappa architecture with a free version of Striim’s unified data integration and streaming platform.









Let's personalize your content