
Toward a Data Mesh (part 2) : Architecture & Technologies
François Nguyen
MARCH 22, 2021
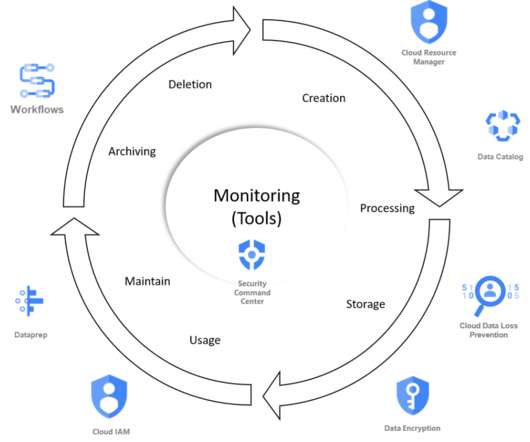
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How do we build data products ? How can we interoperate between the data domains ? As you can see, this is in the code part where you are building your data pipelines, a misnomer because this is an over simplification.







































Let's personalize your content