
Improving Efficiency Of Goku Time Series Database at Pinterest (Part?—?1)
Pinterest Engineering
NOVEMBER 22, 2023
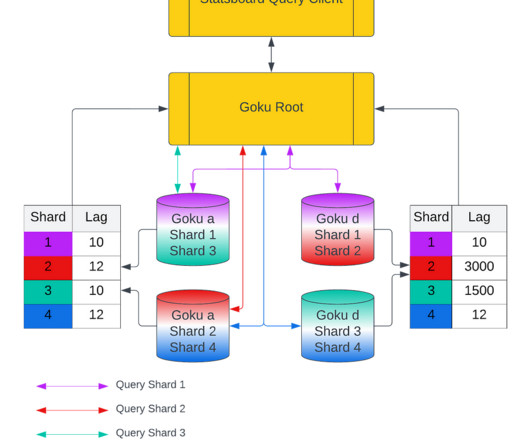
In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components. This is because the synthetic data points would be present in the retry kafka waiting to be pushed into the recovering host by the retry ingestor.
















Let's personalize your content