


Streaming Ingestion for Apache Iceberg With Cloudera Stream Processing
Cloudera
MARCH 2, 2023
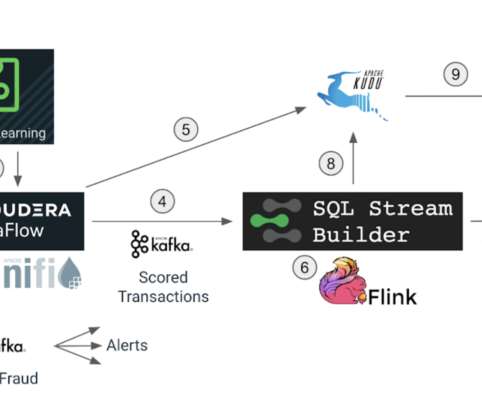
Recently, we announced enhanced multi-function analytics support in Cloudera Data Platform (CDP) with Apache Iceberg. It allows multiple data processing engines, such as Flink, NiFi, Spark, Hive, and Impala to access and analyze data in simple, familiar SQL tables. Currently, Iceberg support in CSP is in technical preview mode.








































Let's personalize your content