
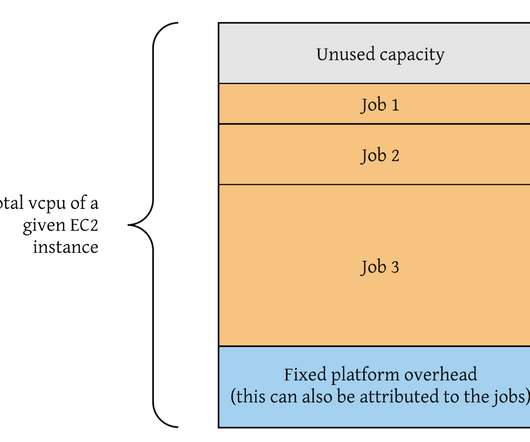
Byte Down: Making Netflix’s Data Infrastructure Cost-Effective
Netflix Tech
JULY 8, 2020
By Torio Risianto, Bhargavi Reddy, Tanvi Sahni, Andrew Park Continue reading on Netflix TechBlog ».
Netflix Tech
JULY 8, 2020
By Torio Risianto, Bhargavi Reddy, Tanvi Sahni, Andrew Park Continue reading on Netflix TechBlog ».

Towards Data Science
JANUARY 26, 2023
This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Before we get started, let’s be clear…when using cloud storage, it is usually not recommended to work with files that are particularly large. The three we will evaluate here are: Python boto3 API, AWS CLI, and S5cmd.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
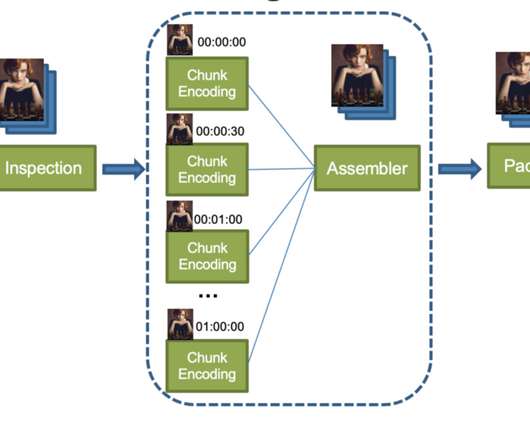
Netflix Tech
SEPTEMBER 24, 2021
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step. Since not all projects are terabytes projects, allocating the largest cloud storage to all packager instances is not an efficient use of cloud resources.

ProjectPro
JANUARY 24, 2023
These benefits compel businesses to adopt cloud data warehousing and take their success to the next level. Some excellent cloud data warehousing platforms are available in the market- AWS Redshift, Google BigQuery , Microsoft Azure , Snowflake , etc. Due to this, combining and contrasting the STRING and BYTE types is impossible.

Tweag
APRIL 19, 2023
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloud storage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure.

Confluent
JULY 10, 2019
jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. It can then send that activity to cloud services like AWS Kinesis, Amazon S3, Cloud Pub/Sub, or Google Cloud Storage and a few JDBC sources. And of course, it can send data to Kafka.

Confluent
MAY 29, 2019
Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google Cloud Storage as Maven artifact repositories. zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0 6 objects dropped. 6 objects created. m2 directory.

Expert insights. Personalized for you.





Let's personalize your content