

Handling Bursty Traffic in Real-Time Analytics Applications
Rockset
MAY 12, 2022
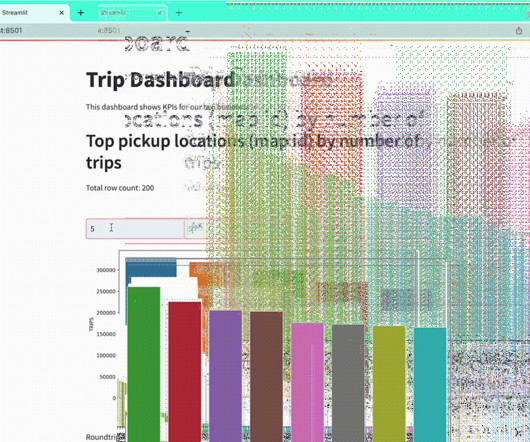
This is the third post in a series by Rockset's CTO Dhruba Borthakur on Designing the Next Generation of Data Systems for Real-Time Analytics. Offloading complex analytics onto data applications. Other databases claim their design provides immunity to bursty data traffic.


























Let's personalize your content