

Building Real-time Machine Learning Foundations at Lyft
Lyft Engineering
JUNE 28, 2023
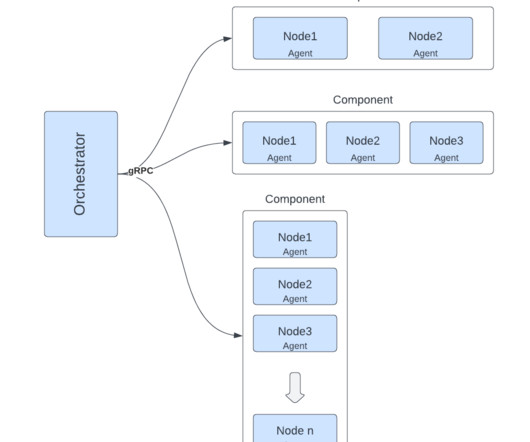
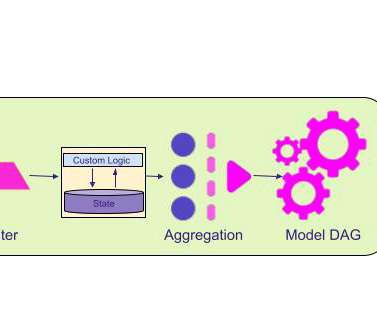
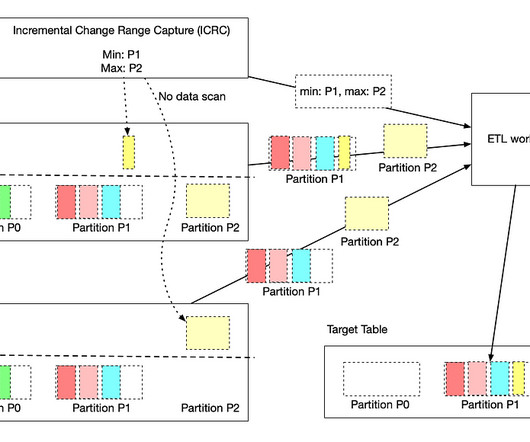
The Event Driven Decisions capability in particular turned out to be general enough as to be applicable to a wide range of use cases. At the time of writing, a Mapping team is working to utilize theEvent Driven Decisions product to rebuild Lyft’s Traffic infrastructure by aggregating data per geohash and applying a model.


















Let's personalize your content