

Webinar Summary: Data Mesh and Data Products
DataKitchen
MAY 4, 2023
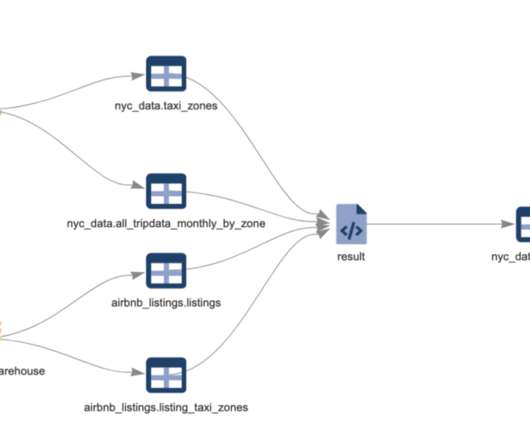
Webinar Summary: DataOps and Data Mesh Chris Bergh, CEO of DataKitchen, delivered a webinar on two themes – Data Products and Data Mesh. Finally, Bergh explained that analysts use the data, and they may have a self-service layer where they can access the data they need to analyze. Watch the webinar today!






























Let's personalize your content