

Accelerate Your Machine Learning Workflows in Snowflake with Snowpark ML
Snowflake
JANUARY 23, 2024
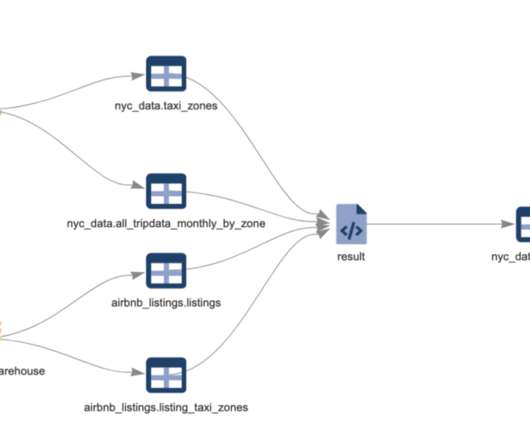
Snowpark ML Operations: Model management The path to production from model development starts with model management, which is the ability to track versioned model artifacts and metadata in a scalable, governed manner. The Snowpark Model Registry API provides simple catalog and retrieval operations on models.










Let's personalize your content