

Modern Data Engineering
Towards Data Science
NOVEMBER 4, 2023
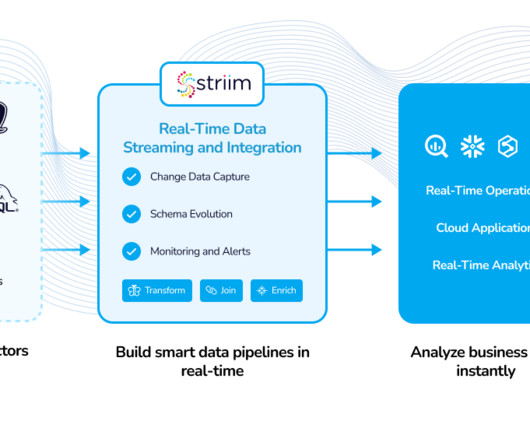
Indeed, datalakes can store all types of data including unstructured ones and we still need to be able to analyse these datasets. What I like about it is that it makes it really easy to work with various data file formats, i.e. SQL, XML, XLS, CSV and JSON. You can change these # to conform to your data. Datalake example.














Let's personalize your content