
Deployment of Exabyte-Backed Big Data Components
LinkedIn Engineering
DECEMBER 19, 2023
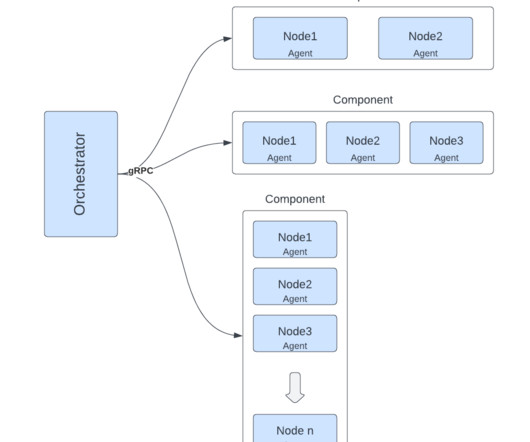
Our RU framework ensures that our big data infrastructure, which consists of over 55,000 hosts and 20 clusters holding exabytes of data, is deployed and updated smoothly by minimizing downtime and avoiding performance degradation. This metadata includes the namespace, file permissions, and the mapping of data blocks to datanodes.


















Let's personalize your content