
5 Reasons Why ETL Professionals Should Learn Hadoop
ProjectPro
SEPTEMBER 30, 2014
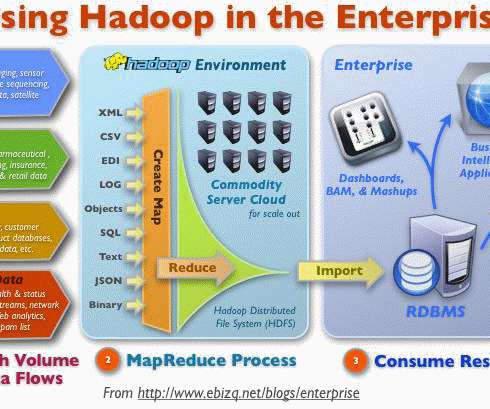
Hadoop’s significance in data warehousing is progressing rapidly as a transitory platform for extract, transform, and load (ETL) processing. Mention about ETL and eyes glaze over Hadoop as a logical platform for data preparation and transformation as it allows them to manage huge volume, variety, and velocity of data flawlessly.









Let's personalize your content