
How to get started with dbt
Christophe Blefari
MARCH 1, 2023
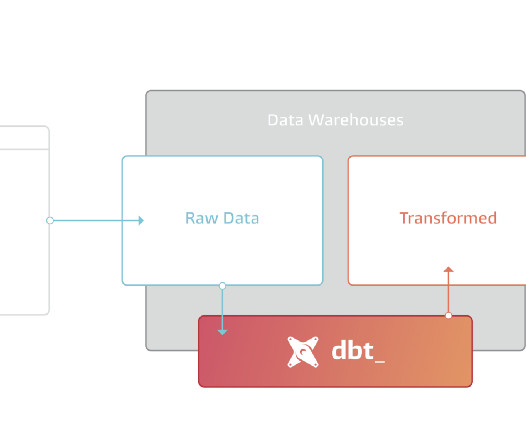
dbt Core is an open-source framework that helps you organise data warehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. This switch has been lead by modern data stack vision.































Let's personalize your content