
How to Design a Modern, Robust Data Ingestion Architecture
Monte Carlo
MAY 28, 2024
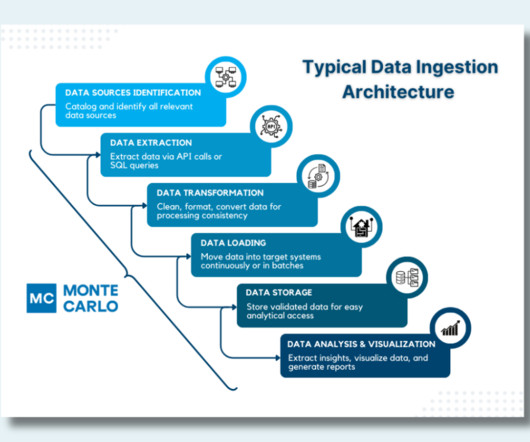
In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability. Data Validation : Perform quality checks to ensure the data meets quality and accuracy standards, guaranteeing its reliability for subsequent analysis.
































Let's personalize your content