

What is a Data Pipeline?
Grouparoo
OCTOBER 26, 2021
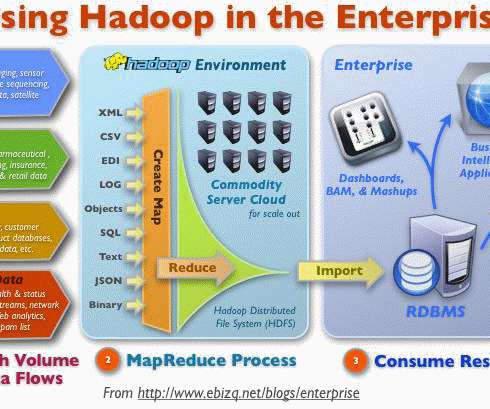
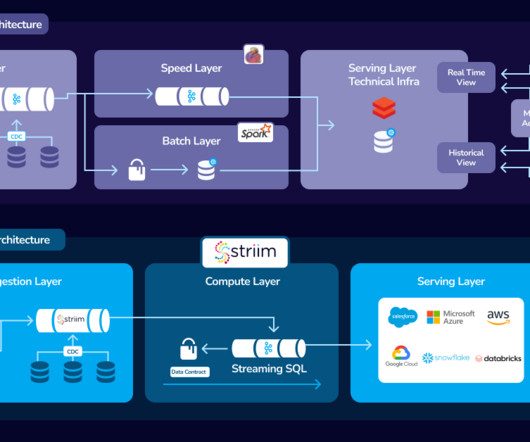
The choice of tooling and infrastructure will depend on factors such as the organization’s size, budget, and industry as well as the types and use cases of the data. Data Pipeline vs ETL An ETL (Extract, Transform, and Load) system is a specific type of data pipeline that transforms and moves data across systems in batches.








Let's personalize your content