
Using Kappa Architecture to Reduce Data Integration Costs
Striim
AUGUST 31, 2023
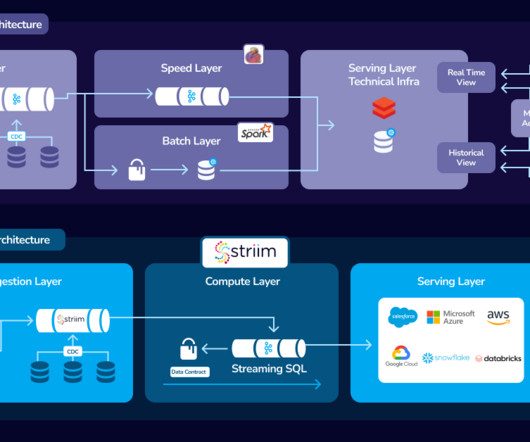
Showing how Kappa unifies batch and streaming pipelines The development of Kappa architecture has revolutionized data processing by allowing users to quickly and cost-effectively reduce data integration costs. Stream processors, storage layers, message brokers, and databases make up the basic components of this architecture.









Let's personalize your content