

97 things every data engineer should know
Grouparoo
OCTOBER 6, 2021
Tianhui Michael Li The Three Rs of Data Engineering by Tobias Macey Data testing and quality Automate Your Pipeline Tests by Tom White Data Quality for Data Engineers by Katharine Jarmul Data Validation Is More Than Summary Statistics by Emily Riederer The Six Words That Will Destroy Your Career by Bartosz Mikulski Your Data Tests Failed!
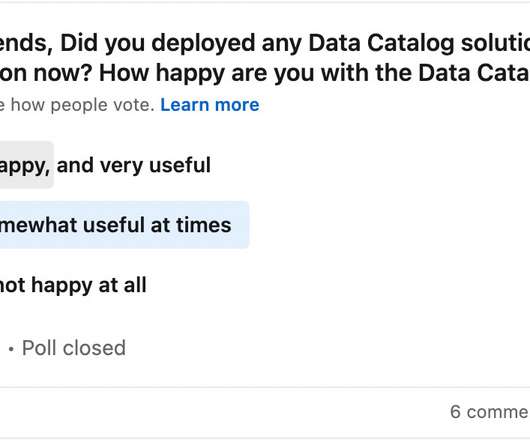












Let's personalize your content