
Data Pipeline Observability: A Model For Data Engineers
Databand.ai
JUNE 28, 2023
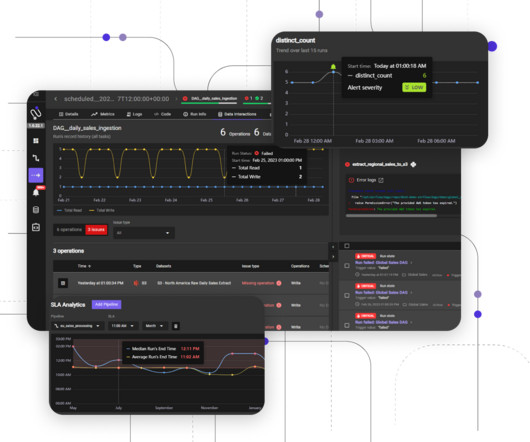
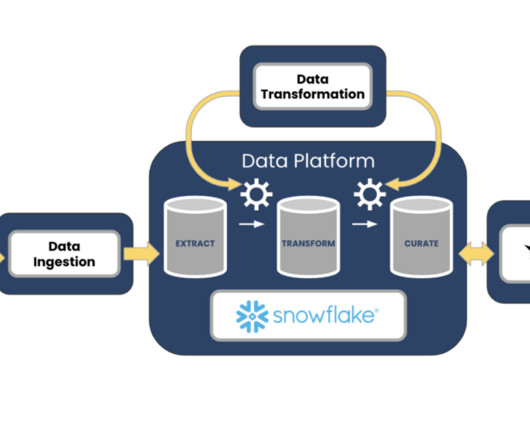
Data Pipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Data pipeline observability is your ability to monitor and understand the state of a data pipeline at any time. We believe the world’s data pipelines need better data observability.




























Let's personalize your content