

Announcing New Innovations for Data Warehouse, Data Lake, and Data Lakehouse in the Data Cloud
Snowflake
NOVEMBER 2, 2023
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Use cases change, needs change, technology changes – and therefore data infrastructure should be able to scale and evolve with change.













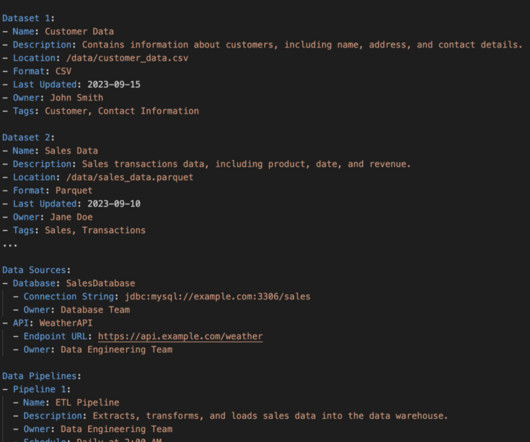



































Let's personalize your content