

4 Key Patterns to Load Data Into A Data Warehouse
Start Data Engineering
AUGUST 17, 2021
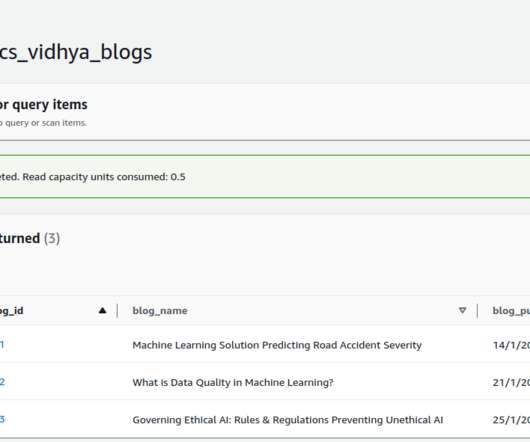
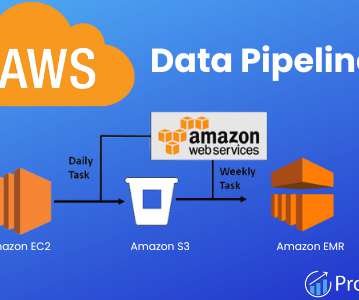
Batch Data Pipelines 1.1 Process => Data Warehouse 1.2 Process => Cloud Storage => Data Warehouse 2. Near Real-Time Data pipelines 2.1 Data Stream => Consumer => Data Warehouse 2.2 Near Real-Time Data pipelines 2.1 If you are wondering













































Let's personalize your content