
Data Engineering Zoomcamp – Data Ingestion (Week 2)
Hepta Analytics
FEBRUARY 14, 2022
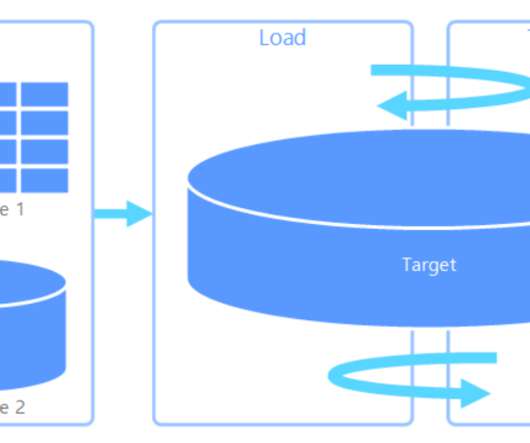
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to data ingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our data ingestion design.
























Let's personalize your content