


ML Training and Deployment Pipeline Using Databricks
Ripple Engineering
MARCH 30, 2023
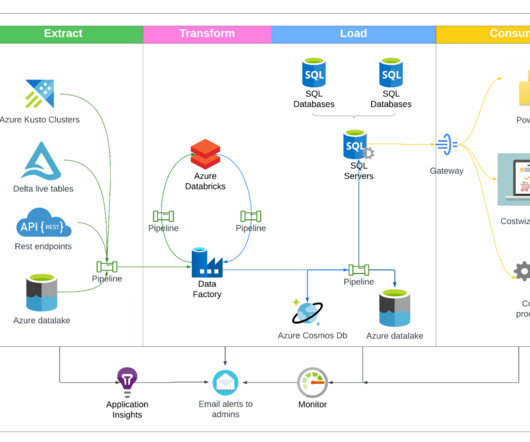
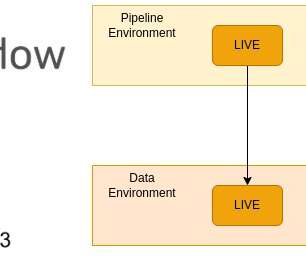
and we needed a managed solution that would help us deliver models to product use cases within a short amount of time, which led us to choose Databricks. This blog outlines Ripple’s general design and approach for machine learning model lifecycle management using Databricks.










Let's personalize your content