

A Deep Dive into the Latest Performance Improvements of Stateful Pipelines in Apache Spark Structured Streaming
databricks
FEBRUARY 28, 2024
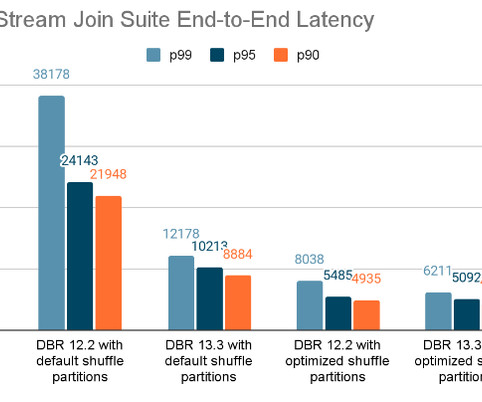
This post is the second part of our two-part series on the latest performance improvements of stateful pipelines. The first part of this.









Let's personalize your content