
Open-Sourcing AvroTensorDataset: A Performant TensorFlow Dataset For Processing Avro Data
LinkedIn Engineering
JUNE 15, 2023
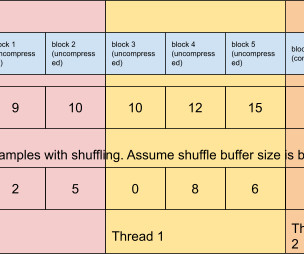
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve data processing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. an array within a map, within a union, etc…). Default is 128 * 1024 (128KB).

















Let's personalize your content