
What is Data Engineering? Everything You Need to Know in 2022
phData: Data Engineering
JANUARY 3, 2022
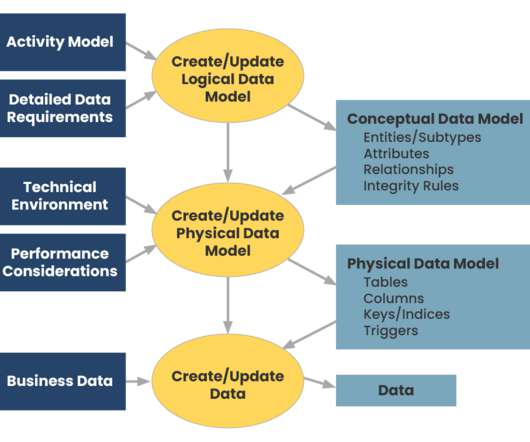
This involves: Building data pipelines and efficiently storing data for tools that need to query the data. Analyzing the data, ensuring it adheres to data governance rules and regulations. Understanding the pros and cons of data storage and query options. Data must also be performant.









Let's personalize your content