

How we shaved 90 minutes off our longest running model
dbt Developer Hub
AUGUST 17, 2022
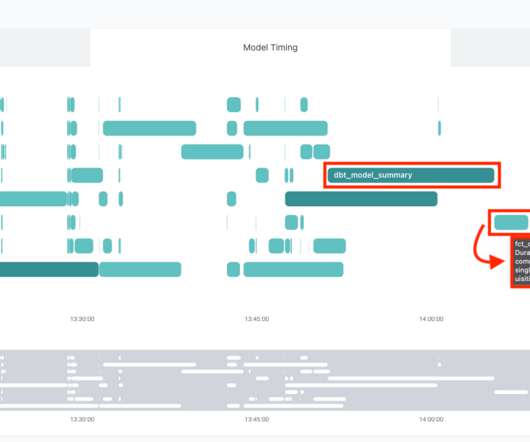
When running a job that has over 1,700 models, how do you know what a “good” runtime is? While there are many possible answers depending on dataset size, complexity of modeling, and historical run times, the crux of the matter is normally “did you hit your SLAs”? The model fct_dbt_invocations takes, on average, 1.5 hours to run.









Let's personalize your content