

Top Data Lake Vendors (Quick Reference Guide)
Monte Carlo
APRIL 24, 2023
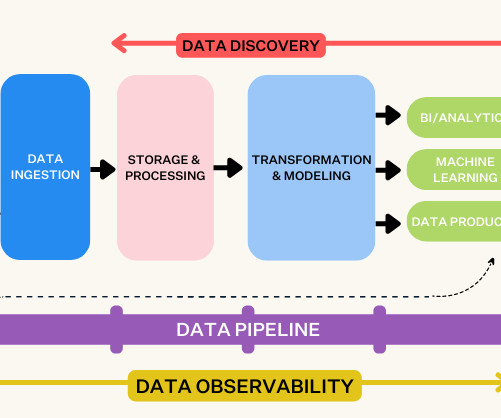
Data lakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.





















Let's personalize your content