

Data Pipeline- Definition, Architecture, Examples, and Use Cases
ProjectPro
DECEMBER 7, 2021
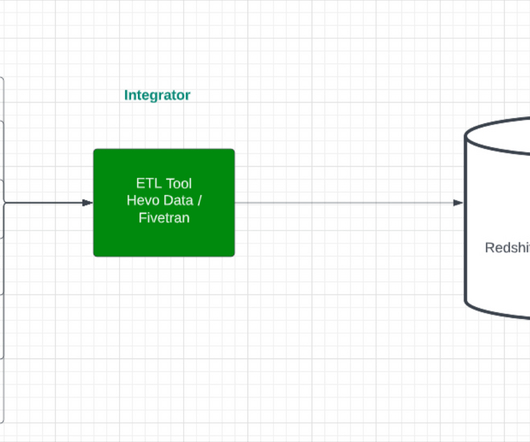
Data pipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a Data Pipeline? The Importance of a Data Pipeline What is an ETL Data Pipeline?













Let's personalize your content