

ELT Explained: What You Need to Know
Ascend.io
NOVEMBER 21, 2023
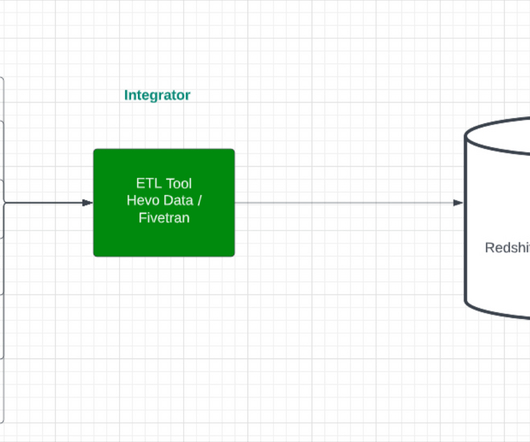
Extract The initial stage of the ELT process is the extraction of data from various source systems. This phase involves collecting raw data from the sources, which can range from structured data in SQL or NoSQL servers, CRM and ERP systems, to unstructured data from text files, emails, and web pages.










Let's personalize your content