

Building Real-time Machine Learning Foundations at Lyft
Lyft Engineering
JUNE 28, 2023
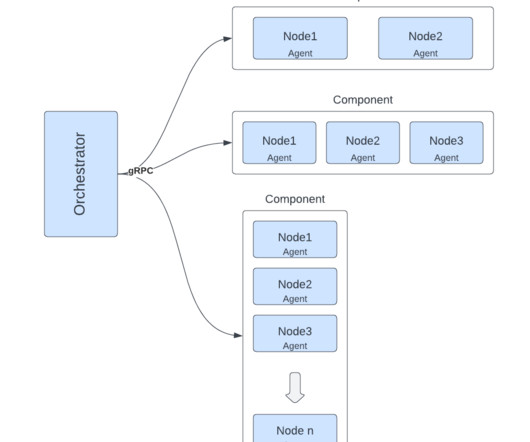
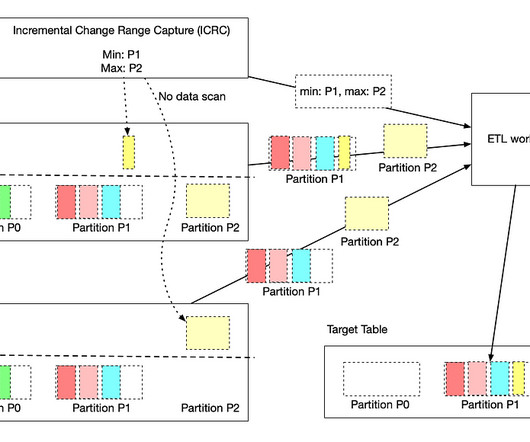
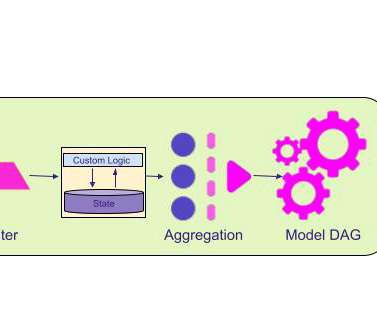
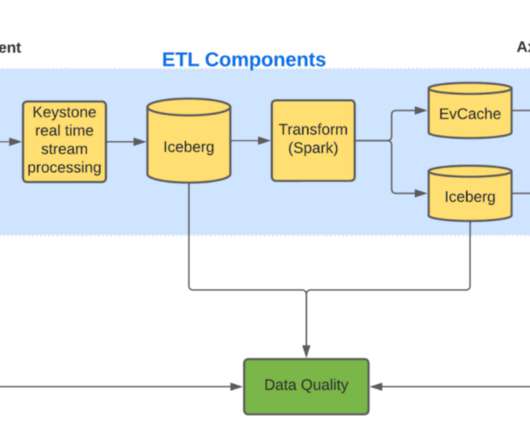
Our goal was to develop foundations that would enable the hundreds of ML developers at Lyft to efficiently develop new models and enhance existing models with streaming data. In this blog post, we will discuss what we built in support of that goal and some of the lessons we learned along the way. register_feature(feature_definition).add_sink(feature_sink)














Let's personalize your content