

How Snowflake Enhanced GTM Efficiency with Data Sharing and Outreach Customer Engagement Data
Snowflake
APRIL 9, 2024
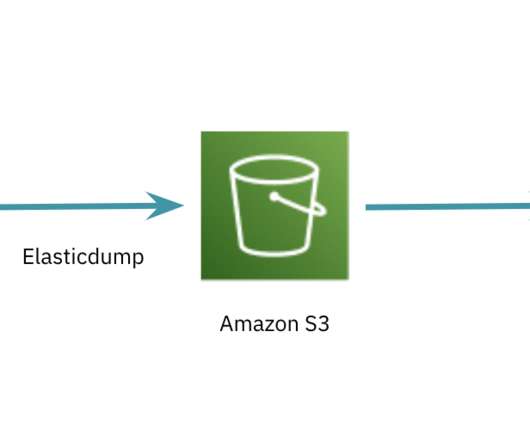
However, that data must be ingested into our Snowflake instance before it can be used to measure engagement or help SDR managers coach their reps — and the existing ingestion process had some pain points when it came to data transformation and API calls. Outcome data goes back into the system to train the model.


















Let's personalize your content