
Building Trust and Combating Abuse On Our Platform
LinkedIn Engineering
DECEMBER 20, 2023
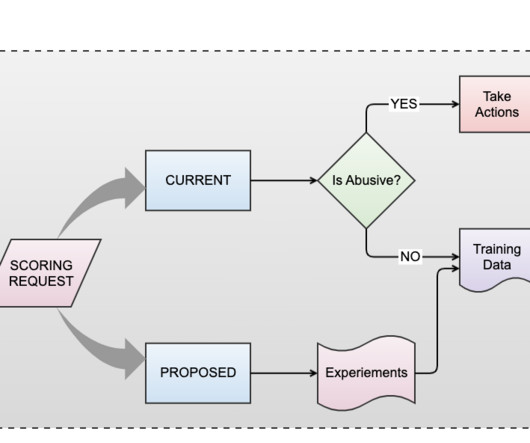
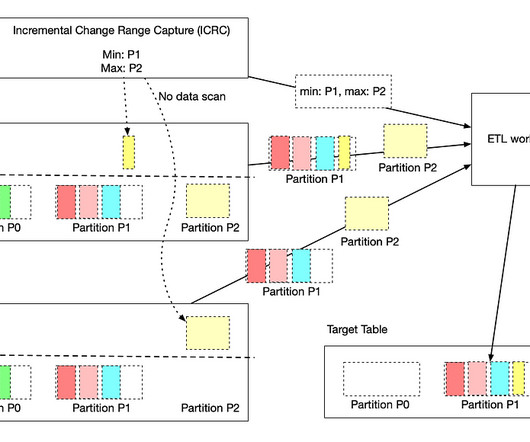
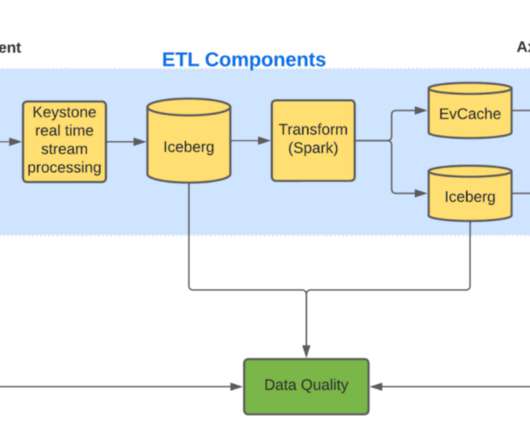
By leveraging cutting-edge technologies, machine learning algorithms, and a dedicated team, we remain committed to ensuring a secure and trustworthy space for professionals to connect, share insights, and foster their career journeys. At the core of inference at scale lies the fusion of ML with a wealth of data.


















Let's personalize your content