
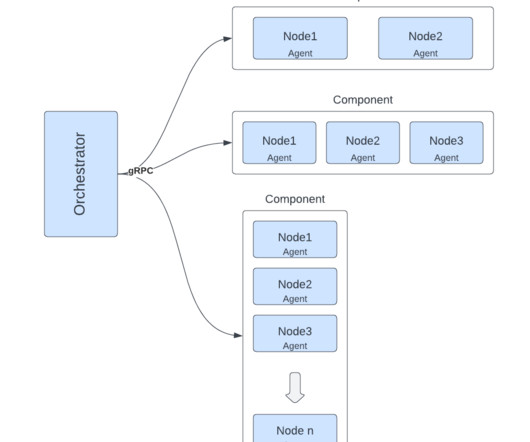
Deployment of Exabyte-Backed Big Data Components
LinkedIn Engineering
DECEMBER 19, 2023
Co-authors: Arjun Mohnot , Jenchang Ho , Anthony Quigley , Xing Lin , Anil Alluri , Michael Kuchenbecker LinkedIn operates one of the world’s largest Apache Hadoop big data clusters. Historically, deploying code changes to Hadoop big data clusters has been complex. Accessibility of all namenodes. 0 missing blocks.























Let's personalize your content