
Improving Recruiting Efficiency with a Hybrid Bulk Data Processing Framework
LinkedIn Engineering
JANUARY 19, 2024
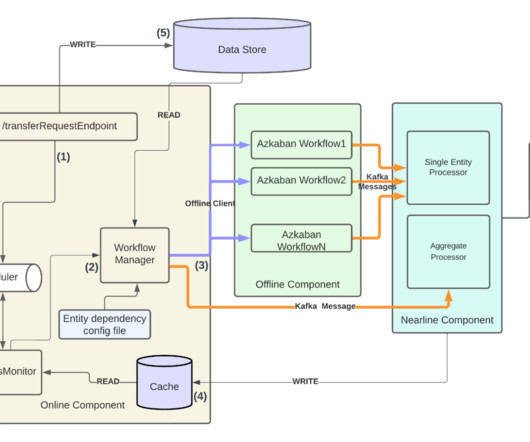
Co- Authors: Aditya Hedge and Saumi Bandyopadhyay 2022 was a year driven by change for the Talent Acquisition industry, with nearly 50k company mergers and acquisitions completed worldwide. With our new data processing framework, we were able to observe a multitude of benefits, including 99.9%


















Let's personalize your content