
Functional Data Engineering - A Blueprint
Data Engineering Weekly
DECEMBER 21, 2022
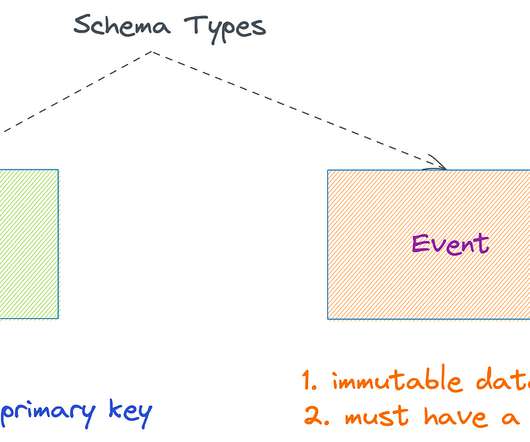
The Rise of Data Modeling Data modeling has been one of the hot topics in Data LinkedIn. Hadoop put forward the schema-on-read strategy that leads to the disruption of data modeling techniques as we know until then. Let’s reference what the data world looked like before the Hadoop era.









Let's personalize your content