
Streaming Market Data with Flink SQL Part II: Intraday Value-at-Risk
Cloudera
MAY 18, 2021
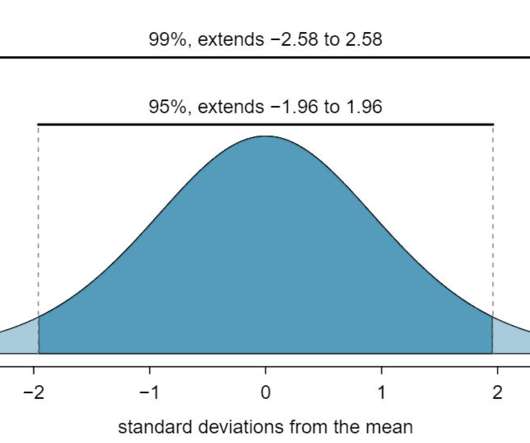
This article is the second in a multipart series to showcase the power and expressibility of FlinkSQL applied to market data. Code and data for this series are available on github. Flink SQL is a data processing language that enables rapid prototyping and development of event-driven and streaming applications.









Let's personalize your content