5 Super Cheat Sheets to Master Data Science
KDnuggets
DECEMBER 8, 2023
The collection of super cheat sheets covers basic concepts of data science, probability & statistics, SQL, machine learning, and deep learning.

KDnuggets
DECEMBER 8, 2023
The collection of super cheat sheets covers basic concepts of data science, probability & statistics, SQL, machine learning, and deep learning.
databricks
DECEMBER 8, 2023
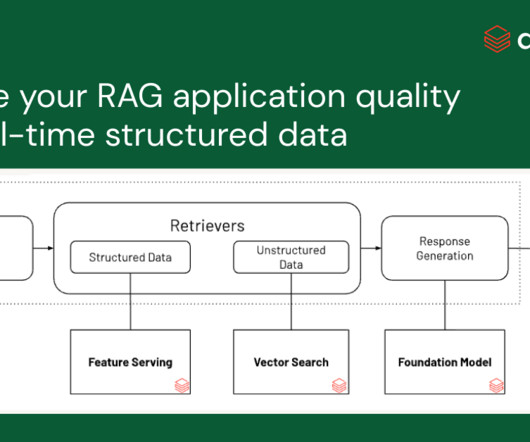
Retrieval Augmented Generation (RAG) is an efficient mechanism to provide relevant data as context in Gen AI applications. Most RAG applications typically use.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

KDnuggets
DECEMBER 8, 2023
OpenAI revolutionizes personal AI customization with its no-code approach to creating custom ChatGPTs.

Towards Data Science
DECEMBER 8, 2023
Clustering: A simple way to group similar rows and prevent unnecessary data processing Continue reading on Towards Data Science »

Advertisement
Generative AI is upending the way product developers & end-users alike are interacting with data. Despite the potential of AI, many are left with questions about the future of product development: How will AI impact my business and contribute to its success? What can product managers and developers expect in the future with the widespread adoption of AI?

KDnuggets
DECEMBER 8, 2023
Google has introduced a revamped AI model that is said to outperform ChatGPT. Let’s learn more.
databricks
DECEMBER 8, 2023
Enterprise leaders are turning to the Databricks Data Intelligence Platform to create a centralized source of high-quality data that business teams can leverage.
Data Engineering Digest brings together the best content for data engineering professionals from the widest variety of industry thought leaders.

Precisely
DECEMBER 8, 2023
The past few years have been transformative, with global events reshaping our personal and professional lives. From a rapidly shifting regulatory environment to volatile economic conditions, today’s business leaders are faced with challenges unlike any in recent memory. In the midst of this turbulence, there has been a pronounced shift toward data-centric strategies.

Towards Data Science
DECEMBER 8, 2023
Leverage some simple equations to generate related columns in test tables. Image generated with DALL-E 3 I’ve recently been playing around with Databricks Labs Data Generator to create completely synthetic datasets from scratch. As part of this, I’ve looked at building sales data around different stores, employees, and customers. As such, I wanted to create relationships between the columns I was artificially populating — such as mapping employees and customers to a certain store.
Striim
DECEMBER 8, 2023
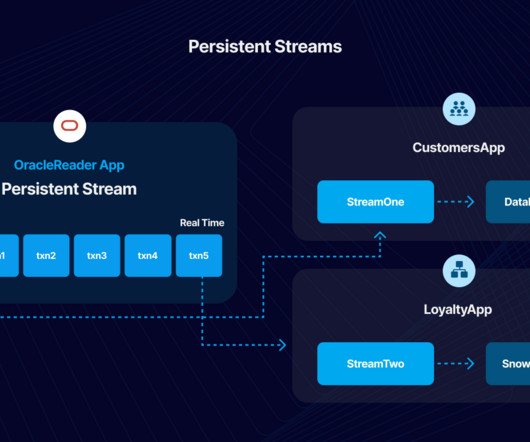
Note: To follow best practices guide, you must have the Persisted Streams add-on in Striim Cloud or Striim Platform. Introduction Change Data Capture (CDC) is a critical methodology, particularly in scenarios demanding real-time data integration and analytics. CDC is a technique designed to efficiently capture and track changes made in a source database, thereby enabling real-time data synchronization and streamlining the process of updating data warehouses, data lakes, or other systems.

Monte Carlo
DECEMBER 8, 2023
What’s something you never want your data to be? Mysterious. The best starting place to make sure you really know your data is, well, your data’s starting place – wherever that may be. For data teams, it’s essential to know your data from the source throughout its entire lifecycle. But, as data moves and is transformed through the pipeline, it can become increasingly complex to trace its journey.

Advertisement
Many organizations today are unlocking the power of their data by using graph databases to feed downstream analytics, enahance visualizations, and more. Yet, when different graph nodes represent the same entity, graphs get messy. Watch this essential video with Senzing CEO Jeff Jonas on how adding entity resolution to a graph database condenses network graphs to improve analytics and save your analysts time.
Striim
DECEMBER 8, 2023
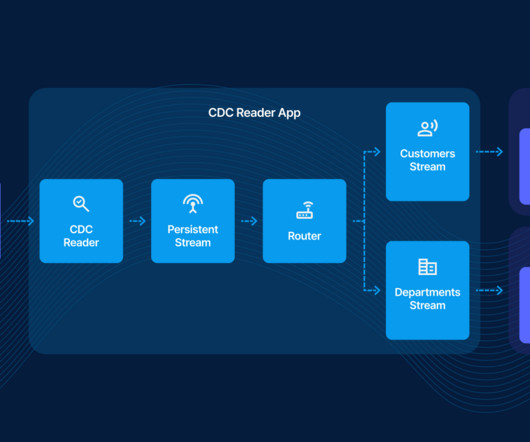
In today’s data-driven business landscape, the ability to effectively capture and utilize real-time data is paramount. Change Data Capture (CDC) is not just a technical process; it’s a gateway to unparalleled business efficiency and intelligence. Let’s explore how Striim’s ‘Read Once, Write Everywhere’ CDC pattern is revolutionizing how businesses handle data.

Monte Carlo
DECEMBER 8, 2023
What’s something you never want your data to be? Mysterious. The best starting place to make sure you really know your data is, well, your data’s starting place – wherever that may be. For data teams, it’s essential to know your data from the source throughout its entire lifecycle. But, as data moves and is transformed through the pipeline, it can become increasingly complex to trace its journey.

Expert insights. Personalized for you.






Let's personalize your content