

Your Generative AI LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers
DataKitchen
FEBRUARY 27, 2024
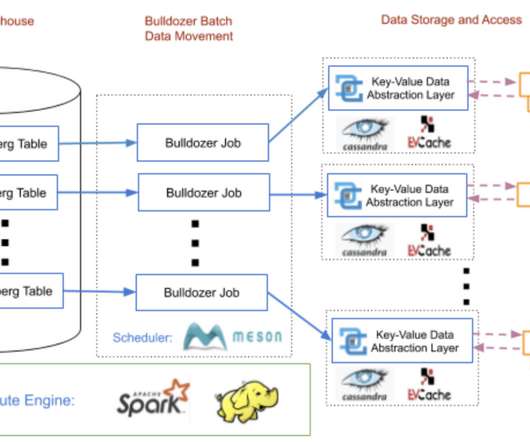
Embracing DataOps for Enhanced Data Journey Management The complexity of managing Data Journeys, especially in RAG and LLMs, underscores the importance of embracing DataOps principles. DataOps provides a framework for automating and optimizing data workflows, emphasizing collaboration, monitoring, and continuous improvement.











Let's personalize your content