
Toward a Data Mesh (part 2) : Architecture & Technologies
François Nguyen
MARCH 22, 2021
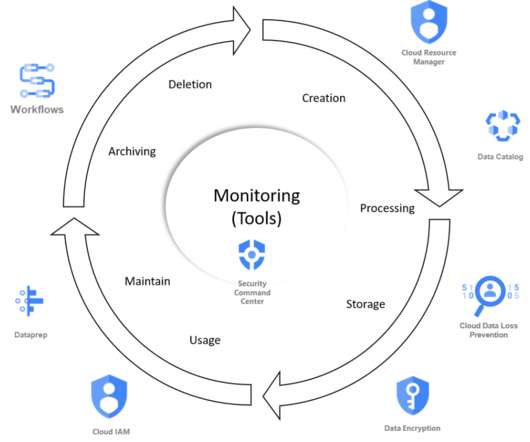
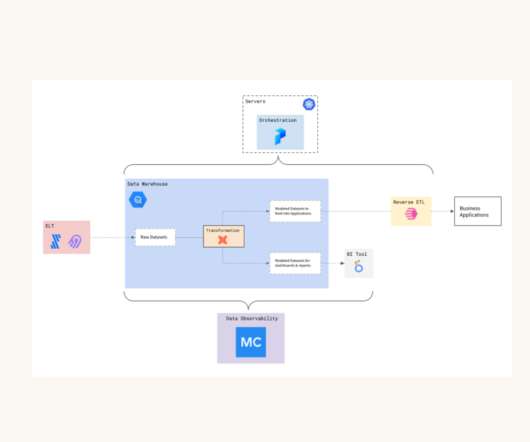
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How can we interoperate between the data domains ? How do we govern all these data products and domains ? It will be illustrated with our technical choices and the services we are using in the Google Cloud Platform.











Let's personalize your content