
From Big Data to Better Data: Ensuring Data Quality with Verity
Lyft Engineering
OCTOBER 3, 2023
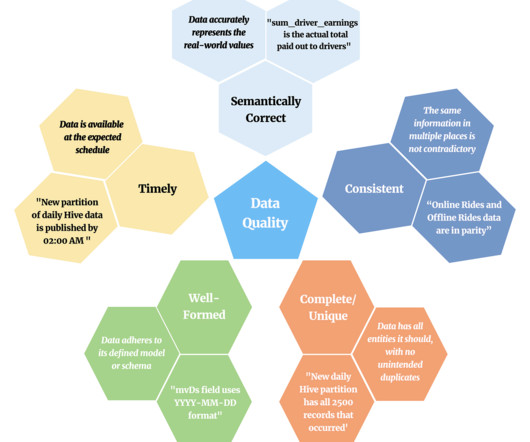
In this post we will define data quality at a high-level and explore our motivation to achieve better data quality. We will then introduce our in-house product, Verity, and showcase how it serves as a central platform for ensuring data quality in our Hive Data Warehouse. What and Where is Data Quality?
















Let's personalize your content