
[O’Reilly Book] Chapter 1: Why Data Quality Deserves Attention Now
Monte Carlo
AUGUST 31, 2023
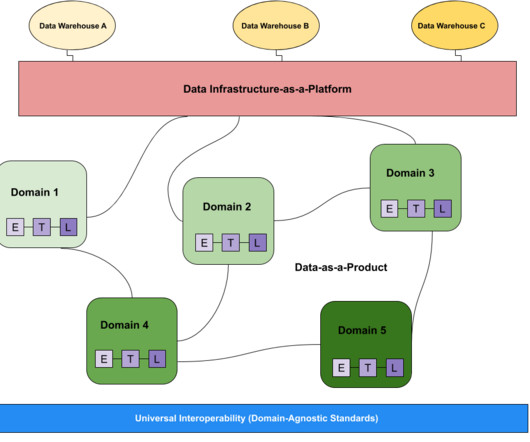
As the data analyst or engineer responsible for managing this data and making it usable, accessible, and trustworthy, rarely a day goes by without having to field some request from your stakeholders. But what happens when the data is wrong? In our opinion, data quality frequently gets a bad rep.











Let's personalize your content