

AI Implementation: The Roadmap to Leveraging AI in Your Organization
Ascend.io
JANUARY 10, 2024
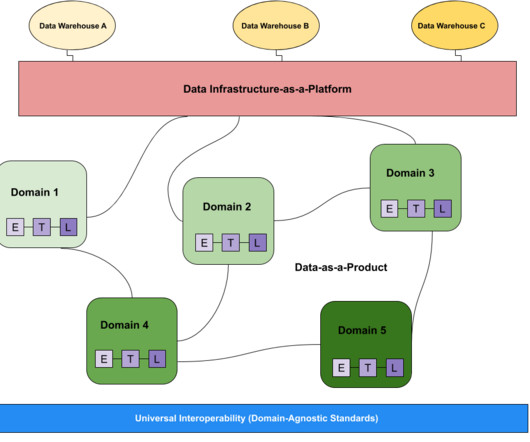
AI models are only as good as the data they consume, making continuous data readiness crucial. Here are the key processes that need to be in place to guarantee consistently high-quality data for AI models: Data Availability: Establish a process to regularly check on data availability. Actionable tip?








Let's personalize your content