

5 Layers of Data Lakehouse Architecture Explained
Monte Carlo
JANUARY 5, 2024
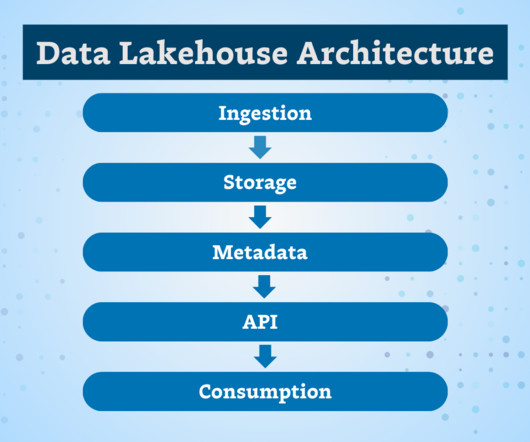
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. API layer 5. A visualization of the flow of data in data lakehouse architecture vs. data warehouse and data lake.




















Let's personalize your content