

Creating Value With a Data-Centric Culture: Essential Capabilities to Treat Data as a Product
Ascend.io
JUNE 8, 2023
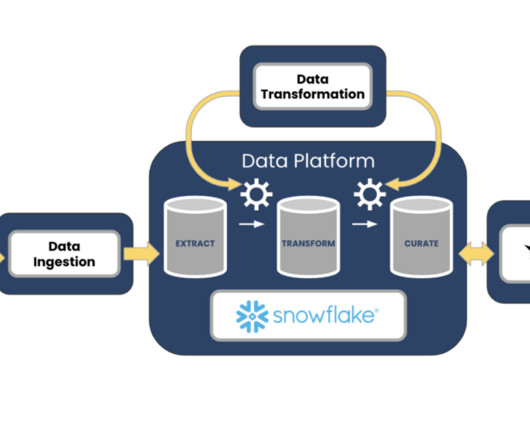
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. Data Pipelines Data pipelines are the indispensable backbone for the creation and operation of every data product.











Let's personalize your content