
Data Engineering Zoomcamp – Data Ingestion (Week 2)
Hepta Analytics
FEBRUARY 14, 2022
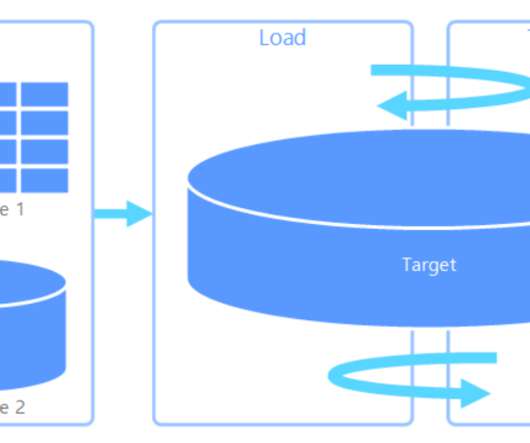
The data ingestion takes less time compared to ETL. It is also preferred when the use case has more diverse business intelligence. When the business intelligence needs change, they can go query the raw data again. ELT: source Data Lake vs Data Warehouse Data lake stores raw data.












Let's personalize your content