

A Cost-Effective Data Warehouse Solution in CDP Public Cloud – Part1
Cloudera
FEBRUARY 9, 2021
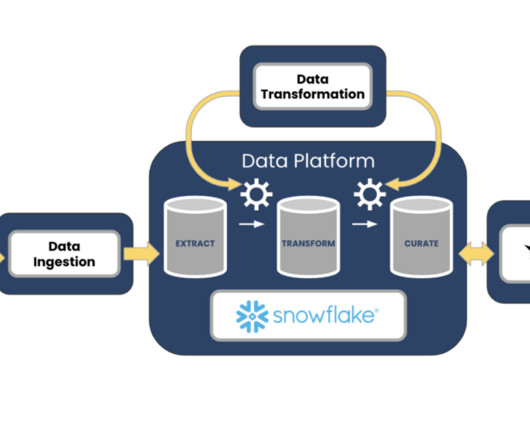
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analytic applications are able to turn the latest data into instant business insights. Design Detail.











Let's personalize your content